This project was part of a many-school competition called QuantQuest hosted by the Goldman Sachs Quantitative Investment Strategies Divison in which I placed in 2nd place out of teams from universities like Columbia, Princeton, MIT, NYU Stern, and Yale. It involved a simple open-ended task using a complex solution using a natural language processing method. The specific task was to create a dynamic (not hard-coded) program which outputs a link matrix of nonnegative correlations between all S&P 500 companies to each other and uses only data found on Wikipedia and any natural language processing method of your choice. To understand the problem, I found all the available data on Wikipedia on the S&P 500 companies and also saw that the given table of S&P 500 companies on Wikipedia included hyperlinks on the majority of company names which led to the company's Wikipedia page. This led me to realize that I could leverage this data by scraping the hyperlinks and using the company pages to perform some sort of natural language processing to compare the pages of 2 different companies, roughly 500x500 times to get all the links of the matrix. For the companies without Wikipedia pages I based the comparison of the companies on the information on sector, subindustry, and company size with unsymmetric weights between the 3. This information was readily available for in the Wikipedia table of the list of S&P 500 companies.
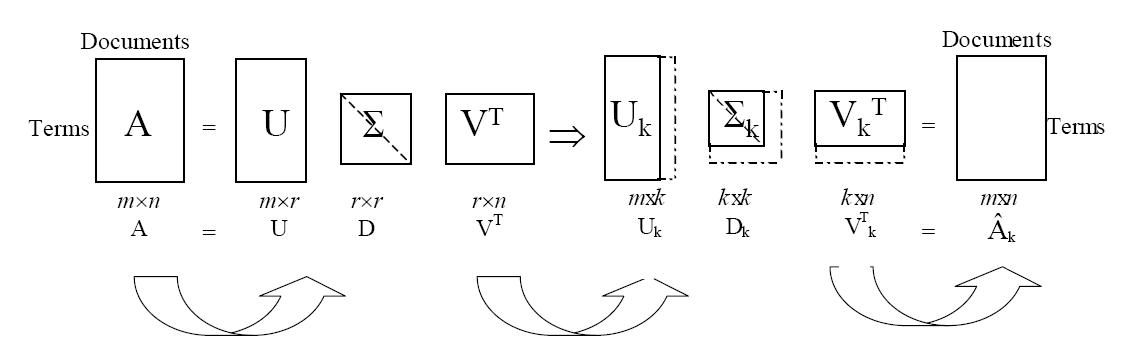
Now, for the more exciting, most interesting part of the project, I was to find and choose a natural language processing algorithm that would effectively correlate information about one company to another to accurately capture any potential correlations in the companys' stock prices. Researching what was out there, I found n-grams, Latent Semantic Indexing (LSI), and Latent Dirichlet Allocation (LDA) to be the most highly effective natural language processing algorithms. From these, I chose to use Latent Semantic Indexing because it reduces the probability of finding false similarities that n-grams has a propensity for and does not require a huge corpus (an extensive dictionary of topic modeling training data) which takes an immense amount of computing power to contribute an accurate result. The technical model of LSI is shown in the figures below and a deeper understanding of my implementation can be obtained from my Presentation. To see the whole program with a sample result can be found on GitHub.
Tools Used:
Python
BeautifulSoup & urllib2 (for web scraping)
NumPy, SciPy, & MatPlotLib (to handle, manipulate, and store the data)
Gensim & NLTK (for machine learning model)